
 SQLD - SQL 기본 [TCL]
SQLD - SQL 기본 [TCL]
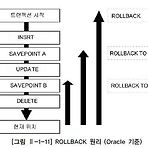
1. 트랜잭션 개요- 데이터베이스의 논리적 연산단위- 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 의미한다.- 하나의 트랜잭션에는 하나 이상의 SQL 문장이 포함된다.- 트랜재션은 분할할 수 없는 최소의 단위이다.- 따라서, 전부 적용하거나 전부 축소 즉, 트랜잭션은 ALL or NOTHING - 트랜잭션을 컨트롤 하는 TCL (TRANSACTION CONTROL LANGUAGE)- 커밋 (COMMIT) : 올바르게 반영된 데이터를 데이터베이스에 반영시키는 것- 롤백 (ROLLBACK) : 트랜잭션 시작 이전의 상태로 되돌리는 것- 저장점 (SAVEPOINT) : - 트랜잭션 대상이 되는 SQL- UPDATE, INSERT, DELETE 등 데이터를 수정하는 DML문- SELECT ..
- DML이란? 자료들을 입력, 수정, 삭제, 조회하는 명령어 (INSERT, UPDATE, DELETE, SELECT) 1. INSERT - INSERT INTO 테이블명 (컬럼리스트) VALUES (컬럼리스트에 넣을 값); - 해당 컬럼과 입력값을 1:1 Mapping 하여 입력한다. - 컬럼의 데이터가 문자 유형일 경우 ‘ (single quotation)로 입력할 값을 입력하낟. 숫자일 경우 붙이지 않는다. 2. UPDATE - UPDATE 테이블명 SET 컬럼명 = 값; 3. DELETE - DELETE FROM 테이블명 4. SELECT - SELECT [ALL/DISTINCT] 컬럼, 컬럼, … FROM 테이블명 - ALL : Default 옵션이므로 별도로 표시하지 않아도 된다. 중복된 데..
1. 데이터 유형 - 숫자 타입 ANSI/ISO 기준 : NUMERIC, DEMICAL, DEC, SMALLINT, INTEGER,INT, BIGINT, FLOAT, REAL, DOUBLE PRECISION SQL Server와 Sybase : 작은 정수형, 정수형, 큰 정수형, 실수형 등 + MONEY, SMALLMONEY Oracle : 숫자형 타입에 대해서 NUMBER 한 가지 숫자 타입의 데이터 유형만 지원 - 벤더에서 ANSI/ISO 표준을 사용할 떄는 기능을 중심으로 구현하므로, 일반적으로 표준과 다른 용어를 사용하는 것이 허용 Ex) NUMERIC -> NUMBER , WINDOW FUCTION ->ANALYTIC/RANK FUNCTION - 테이블의 칼럼이 가지고 있는 대표적인 4가지 데이..
 SQLD - SQL 기본 [관계형 데이터베이스 개요]
SQLD - SQL 기본 [관계형 데이터베이스 개요]
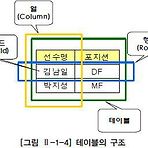
1. 데이터베이스- 특정 기업이나 조직 또는 개인이 필요에 의해 데이터를 일정한 형태로 저장해 놓은 것- DBMS(Database Management System) : 데이터베이스 관리 소프트웨어n 데이터베이스의 발전- 1960년대 : 플로우차트 중심의 개발 방법- 1970년대 : 계층형(Hierarchical) 데이터베이스, 망형(Network) 데이터베이스 같은 제품- 1980년대 : 관계형 데이터베이스가 상용화되었으며 Oracle, Sybase, DB2와 같은 제품- 1990년대 : 객체 관계형 데이터베이스로 Oracle, Sybase, Informix, DB2, Teradata, SQL Server n 관계형 데이터베이스 (Relational Database)- 1970년 영국의 수학자였던 E.F..
 SQLD - 데이터 모델과 성능 [분산 데이터베이스와 성능]
SQLD - 데이터 모델과 성능 [분산 데이터베이스와 성능]
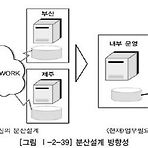
1. 분산 데이터베이스의 개요- 데이터베이스를 연결하는 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역 여러 노드로 위치시켜 사용성/성능 등을 극대화 시킨 데이터베이스- 분산되어 있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임- 물리적 Site 분산, 논리적으로 사용자 통합 공유 2. 분산 데이터베이스의 투명성(Transparency)1) 분할투명성(단편화) : 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단편의 사본이 여러 Site에 저장2) 위치 투명성 : 사용하려는 데이터의 저장 장소 명시 불필요. 위치 정보가 System Catalog 에 유지 ..
 SQLD - 데이터 모델과 성능 [데이터베이스 구조와 성능]
SQLD - 데이터 모델과 성능 [데이터베이스 구조와 성능]
1. 슈퍼/서브타입 모델의 성능고려 방법가. 슈퍼/서브타입 데이터 모델(Extended ER Model)의 개요- 최근 가장 많이 쓰임 (업무를 구성하는 데이터를 공통과 차이점의 특징을 고려하여 효과적으로 표현할 수 있기 때문이다.)- 공통의 부분 => 슈퍼타입- 공통으로부터 상속받아 다른 엔티티와 차이가 있는 속성 => 서브타입- 논리적 데이터 모델에서 이용되는 형태이며, 분석단계에서 많이 쓰이는 모델- 물리적 데이터 모델로 설계시의 문제점이 나타난다. (적당한 노하우가 없어서 나타나며, 1:1타입이 되거나 All in One 타입이 되어버려 성능 저하가 일어난다.) 나. 슈퍼/서브타입 데이터 모델의 변환- 성능저하의 원인 3가지n 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union ..
 SQLD - 데이터 모델과 성능 [대량 데이터에 따른 성능]
SQLD - 데이터 모델과 성능 [대량 데이터에 따른 성능]
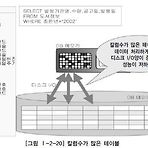
1. 대량 데이터 발생에 따른 테이블 분할 개요- 테이블 분할 설계를 통한 성능 저하의 예방1) 수평분할 : 컬럼 단위로 분할하여 I/O 경감2) 수직분할 : 로우 단위로 분할하여 I/O 경감 - 성능저하의 원인1) 하나의 테이블에 데이터 대량 집중 : 한 테이블에 데이터가 대량으로 집중될 때 테이블 구조가 너무 커져서 효율성이 떨어져 테이버를 처리할 때 디스크 I/O를 많이 유발하게 된다.2) 하나의 테이블에 여러 개의 컬럼 존재 : 이 경우 디스크의 점유량이 높아지고 데이터를 읽는 I/O량이 많아져서 성능이 저하된다.3) 대량의 데이터가 처리되는 테이블의 경우 : SQL문장에서 데이터를 처리하기 위한 I/O의 양이 증가한다. 인덱스를 적절하게 구성하여 이용하면 이를 줄일 수 있다.4) 대량의 데이터가..
1. 반정규화를 통한 성능향상 전략가. 반정규화의 정의- 정규화된 엔티티, 속성, 관계에 대해 시스템의 성능향상, 개발(Development)과 운영(Maintenance)의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미한다.- 협의의 반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법이라고 정의할 수 있고, 좀 더 넓은 의미의 반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정을 의미한다.- 성능이 저하될 것이 예상되는 경우 반정규화를 수행한다. 나. 반정규화의 적용방법1) 반정규화의 대상을 조사한다.l 자주 사용되는 테이블에 접근(Access)하는 프로세스의 수가 많고 항상 일정한 범위만 조회하는 경우에 반정규화를..
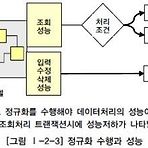 SQLD - 데이터 모델과 성능 [정규화와 성능]
SQLD - 데이터 모델과 성능 [정규화와 성능]
1. 정규화를 통한 성능 향상 전략- 정규화란? 다양한 유형의 검사를 통해 데이터 모델을 좀 더 구조화하고 개선시켜 나가는 절차에 관련된 이론이다. 데이터 모델링을 하면서 정규화를 하는 것은 기본적으로 데이터에 대한 중복성을 제거하여 주고 데이터가 관심사별로 처리되는 경우가 많기 때문에 성능이 향상되는 특징을 가지고 있다.- 데이터처리의 성능이 무엇인지 정확히 구분하여 인식할 필요가 있다. 데이터베이스에서 데이터를 처리할 때 성능이라고 하면 조회 성능과 입력/수정/삭제 성능의 두 부류로 구분된다. 이 두 가지 성능이 모두 우수하면 좋겠지만 데이터 모델을 구성하는 방식에 따라 두 성능이 Trade-Off 되어 나타나는 경우가 많이 있다.- 정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종..
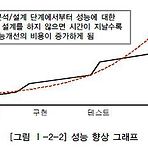 SQLD - 데이터 모델과 성능 [성능 데이터 모델링의 개요]
SQLD - 데이터 모델과 성능 [성능 데이터 모델링의 개요]
1. 성능 데이터 모델링의 정의- 데이터의 용량이 커지고 기업의 의사결정 속도가 빨라질수록 데이터를 처리하는 속도는 빠르게 처리되어야 할 필요성을 반증해준다.- 성능이 저하되는 데이터 모델의 경우 크게 세 가지 경우를 고려하여 그 성능을 향상시킬 수 있다.l 데이터 모델 구조에 의해 성능 저하l 데이터가 대용량이 됨으로 인해 불가피하게 성능 저하l 인덱스 특성을 충분히 고려하지 않고 인덱스를 생성함으로 인해 성능 저하- 성능데이터 모델링은 정규화를 통해서도 수행할 수 있고 인덱스의 특징을 고려해서 칼럼의 순서도 변형할 수 있다.- 대량의 데이터특성에 따라 비록 정규화된 모델이라도 테이블을 수직 또는 수평 분할하여 적용하는 방법도 있고 논리적인 테이블을 물리적인 테이블로 전환할 때 데이터 처리의 성격에 따..